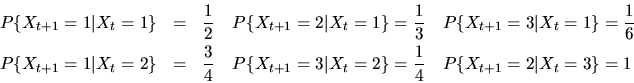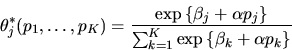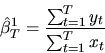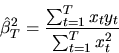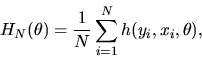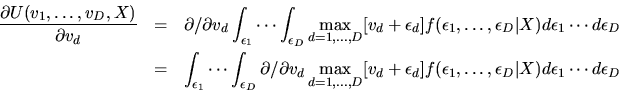Next: About this document ...
Spring 2001 John Rust
Economics 551b 37 Hillhouse, Rm. 27
FINAL EXAM
April 27, 2001
INSTRUCTIONS: Do all Parts I, II and III below. You are
required to answer all questions in Part I, 2 out of 6 questions
in Part II, and 1 out of 4 questions from Part III. Total points for the final
exam is 100. Part I should take about 15
minutes and is worth 15 points. Part II should take about 30 minutes
and is worth 30 points. Part III should take about 60 minutes and is
worth 55 points.
You have 3 hours for the exam, but my expectation that almost all
students will
complete it in two hours.
Part I: 15 minutes, 15 points. Answer all questions below:
1. Suppose
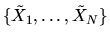 are IID draws from a
are IID draws from a
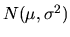 distribution (i.e. a normal
distribution with mean
distribution (i.e. a normal
distribution with mean 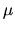 and variance
and variance 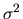 ). Consider the
estimator
). Consider the
estimator
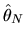 defined by:
defined by:
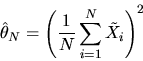 |
(1) |
Which of the
following statements are true and which are false?
- A.
-
is a consistent estimator of .
- B.
-
is an unbiased estimator of .
- C.
-
is a consistent estimator of .
- D.
-
is an unbiased estimator of .
- E.
-
is a consistent estimator or
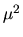 .
.
- F.
-
is an unbiased estimator of .
- G.
-
is an upward biased estimator of .
- H.
-
is a downward biased estimator of .
2. Consider estimation of the linear model
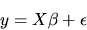 |
(2) |
based on N IID observations
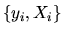 where Xi is a
where Xi is a
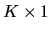 vector of independent variables and yi is a
vector of independent variables and yi is a
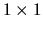 scalar independent variable.
Mark each of the following statements as true or false:
scalar independent variable.
Mark each of the following statements as true or false:
- A.
- The Gauss-Markov Theorem proves that the ordinary
least squares estimator (OLS) it BLUE (Best Linear Unbiased
Estimator).
- B.
- The Gauss-Markov Theorem requires that the error term
in the regression
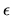 be normally distributed with mean 0 and
variance .
be normally distributed with mean 0 and
variance .
- C.
- The Gauss-Markov Theorem does not apply if the true
regression function does not equal
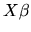 ,
i.e. if
,
i.e. if
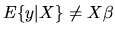 .
.
- D.
- The Gauss-Markov Theorem does not apply if there is
heteroscedasticity.
- E.
- The Gauss-Markov Theorem does not apply if the error term
has a non-normal distribution.
- F.
- The maximum likelihood estimator of
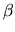 is more efficient
than the OLS estimator of .
is more efficient
than the OLS estimator of .
- G.
- The OLS estimator of
will be unbiased only if the
error terms are distributed independently of X and have mean 0.
- H.
- The maximum likelihood estimator of
is the same as
OLS only in the case where
is normally distributed.
- I.
- The OLS estimator will be a consistent estimator of even if the error term
is not normal and even if there
is heteroscedasticity.
- J.
- The OLS estimator of the asymptotic covariance matrix for ,
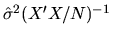 (where
(where
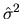 is the sample variance
of
the estimated residuals
is the sample variance
of
the estimated residuals
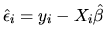 )
is a consistent estimator regardless of whether
is normally
distributed or not.
)
is a consistent estimator regardless of whether
is normally
distributed or not.
- K.
- The OLS estimator of the asymptotic covariance matrix for ,
(where
is the sample variance
of
the estimated residuals
)
is a consistent estimator regardless of whether there is
heteroscedasticity in .
- L.
- If the distribution of
is double exponential,
i.e. if
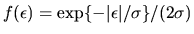 ,
the maximum
likelihood estimator of
is the Least Absolute Deviations
estimator and it is asymptotically efficient relative to the OLS
estimator.
,
the maximum
likelihood estimator of
is the Least Absolute Deviations
estimator and it is asymptotically efficient relative to the OLS
estimator.
- M.
- The OLS estimator cannot be used if the regression function
is misspecified, i.e. if the true regression function
.
- N.
- The OLS estimator will be inconsistent if
and X are correlated.
- O.
- The OLS estimator will be inconsistent if the
dependent variable y is truncated, i.e. if the dependent variable
is actually determined by the relation
![\begin{displaymath}y= \max[0, X\beta + \epsilon] \end{displaymath}](img21.gif) |
(3) |
- P.
- The OLS estimator is inconsistent if
has
a Cauchy distribution, i.e. if the density of
is given
by
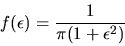 |
(4) |
- Q.
- The 2-stage least squares estimator is a better estimator
than the OLS estimator because it has two stages and is therefore
twice as efficient.
- R.
- If the set of instrumental variables W and the set of
regressors X in the linear model coincide, then 2 stage least squares
estimator of
is the same as the OLS estimator of .
Part II: 30 minutes, 30 points. Answer 2 of the
following 6 questions below.
QUESTION 1 (Probability question) Suppose 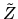 is a
random
vector with a multivariate N(0,I) distribution, i.e.
is a
random
vector with a multivariate N(0,I) distribution, i.e.
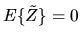 where
0 is a
vector of zeros and
where
0 is a
vector of zeros and
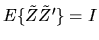 where I is the
where I is the
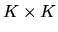 identity matrix. Let M be a
idempotent matrix, i.e. a matrix that satisfies
identity matrix. Let M be a
idempotent matrix, i.e. a matrix that satisfies
Show that
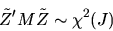 |
(6) |
where 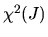 denotes a chi-squared random variable with
J degrees of freedom and
denotes a chi-squared random variable with
J degrees of freedom and
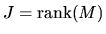 .
Hint: Use the fact that
M has a singular value decomposition,
i.e.
.
Hint: Use the fact that
M has a singular value decomposition,
i.e.
where X' X = I and D is a diagonal matrix whose diagonal elements
are equal to either 1 or 0.
QUESTION 2 (Markov Processes)
- A.
- (10%) Are Markov processes of any use in econometrics? Describe
some examples of how Markov processes are used in econometrics such
as providing models of serially dependent data, as a framework for establishing
convergence of estimators and
proving laws of large numbers, central limit theorems, etc.
and as computational tool for doing simulations.
- B.
- (10%) What is a random walk? Is a random walk always a Markov process?
If not, provide a counter-example.
- C.
- (40%) What is the ergodic or invariant distribution of
a Markov process? Do all Markov processes have invariant
distributions? If not, provide a counterexample of a Markov
process that doesn't have an invariant distribution. Can
a Markov process have more than 1 invariant distribution?
If so, give an example.
- D.
- (40%) Consider the discrete Markov process
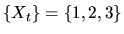 with transition
probability
with transition
probability
Does this process have an invariant distribution? If so,
find all of them.
QUESTION 3 (Consistency of M-estimator)
Consider an M-estimator defined by:
Suppose following two conditions are given
(i) (Identification) For all
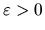
where
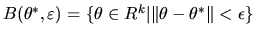 .
.
(ii) (Uniform Convergence)
Prove consistency of the estimator by showing
QUESTION 4 (Time series question)
Suppose 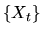 is an ARMA(p,q) process, i.e.
is an ARMA(p,q) process, i.e.
where A(L) is a
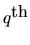 order lag-polynomial
order lag-polynomial
and B(L) is a
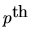 order lag-polynomial
order lag-polynomial
and the lag-operator Lk is defined by
Lk Xt = Xt-k
and
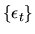 is a white-noise process,
is a white-noise process,
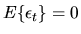 and
(cov(
and
(cov(
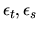 )=0 if
)=0 if 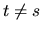 ,
,
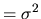 if t=s).
if t=s).
- A.
- (30%) Write down the autocovariance and
spectral density functions for this process.
- B.
- (30%) Show that if p = 0 an autoregression of Xt on
q lags of itself provides a consistent estimate of
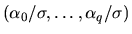 .
Is the autoregression
still consistent if p > 0?
.
Is the autoregression
still consistent if p > 0?
- C.
- (40%) Assume that a central limit
theorem holds, i.e. the distribution of
normalized sums of
to converge in distribution to a normal random variable.
Write down an
expression for the variance of the limiting normal distribution.
QUESTION 5 (Empirical question)
Assume that shoppers always choose only
a single
brand of canned tuna fish from the available selection of Kalternative brands of tuna fish each time they go shopping
at a supermarket. Assume initially that the (true) probability
that the decision-maker chooses brand k is the
same for everybody and is given by
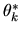 ,
,
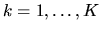 .
Marketing researchers
would like to learn more about these choice probabilities,
.
Marketing researchers
would like to learn more about these choice probabilities,
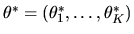 and spend a great deal
of money sampling shoppers' actual tuna fish choices in order
to try to estimate these probabilities. Suppose the Chicken of
the Sea Tuna company
undertook a survey of N shoppers and for each shopper shopping
at a particular supermarket with a fixed set of K brands of
tuna fish, recorded the brand bi chosen by shopper i,
and spend a great deal
of money sampling shoppers' actual tuna fish choices in order
to try to estimate these probabilities. Suppose the Chicken of
the Sea Tuna company
undertook a survey of N shoppers and for each shopper shopping
at a particular supermarket with a fixed set of K brands of
tuna fish, recorded the brand bi chosen by shopper i,
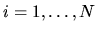 .
Thus, b1=2 denotes the observation that consumer
1 chose tuna brand 2, and b4=K denotes the observation that
consumer 4 chose tuna brand K, etc.
.
Thus, b1=2 denotes the observation that consumer
1 chose tuna brand 2, and b4=K denotes the observation that
consumer 4 chose tuna brand K, etc.
- A.
- (10%) Without doing any estimation, are there any
general
restrictions that you can place on the
parameter
vector
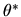 ?
?
- B.
- (10%) Is it reasonable to
suppose that
is the same for everyone? Describe
several factors that could lead different people to have different
probabilities of purchasing different brands of tuna. If you
were a consultant to Chicken of the Sea, what additional data
would you recommend that they collect in order to better predict
the probabilities that consumers buy various brands of tuna? Describe
how you would use this data once it was collected.
- C.
- (20%) Using the observations
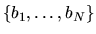 on the
observed brand choices of the sample of N shoppers, write
down an estimator for
(under the assumption that
the ``true'' brand choice probabilities
are the same
for everyone). Is your estimator unbiased?
on the
observed brand choices of the sample of N shoppers, write
down an estimator for
(under the assumption that
the ``true'' brand choice probabilities
are the same
for everyone). Is your estimator unbiased?
- D.
- (20%) What is the maximum likelihood estimator of
? Is the maximum likelihood estimator unbiased?
- E.
- (40%) Suppose Chicken of the Sea Tuna company
also collected data on the prices
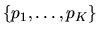 that the supermarket charged for each
of the K different brands of tuna fish. Suppose someone proposed
that the probability of buying brand j was a function of
the prices of all the various brands of tuna,
that the supermarket charged for each
of the K different brands of tuna fish. Suppose someone proposed
that the probability of buying brand j was a function of
the prices of all the various brands of tuna,
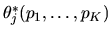 ,
given by:
,
given by:
Describe in general terms
how to estimate the parameters
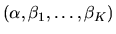 .
If
.
If 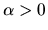 ,
does an increase
in pj decrease or increase the probability that a shopper would buy
brand j?
,
does an increase
in pj decrease or increase the probability that a shopper would buy
brand j?
QUESTION 6 (Regression question)
Let (yt,xt) be IID observations from a regression model
where yt, xt, and
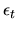 are all
scalars. Suppose that
is normally
distributed with
are all
scalars. Suppose that
is normally
distributed with
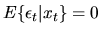 ,
but
,
but
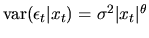 .
Consider the following two estimators for
.
Consider the following two estimators for
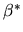 :
:
- A.
- (20%) Are these two estimators consistent estimators of
? Which estimator is more efficient when:
1) if we know a priori that
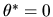 ,
and 2) we don't know ?
Explain your reasoning for full credit.
,
and 2) we don't know ?
Explain your reasoning for full credit.
- B.
- (20%) Write down an asymptotically
optimal estimator for
if we know the value of
a priori.
- C.
- (20%) Write down an asymptotically optimal estimator for
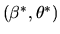 if we don't know the value of
a
priori.
if we don't know the value of
a
priori.
- D.
- (20%) Describe the feasible GLS estimator for
.
Is the feasible GLS estimator asymptotically efficient?
- E.
- (20%) How would your answers to parts A to D change
if you didn't know the distribution of
was normal?
Part III (60 minutes, 55 points). Do 1 out of the
4 questions below.
QUESTION 1 (Hypothesis testing) Consider the GMM estimator with IID data, i.e
the observations
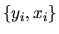 are independent and identically distributed
using the moment condition
are independent and identically distributed
using the moment condition
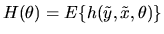 ,
where h is a
,
where h is a
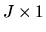 vector of moment conditions and
vector of moment conditions and
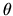 is a
vector of parameters to be estimated.
Assume that the moment conditions are correctly specified, i.e. assume there
is a unique
such that
is a
vector of parameters to be estimated.
Assume that the moment conditions are correctly specified, i.e. assume there
is a unique
such that
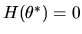 .
Show that in the overidentified case (J >K) that the
minimized value of the GMM criterion function is asymptotically
.
Show that in the overidentified case (J >K) that the
minimized value of the GMM criterion function is asymptotically 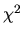 with
J-K degrees of freedom:
with
J-K degrees of freedom:
![\begin{displaymath}N H_N(\hat\theta_N) [\hat\Omega_N]^{-1} H_N(\hat\theta_N)_{\Longrightarrow \atop d} \chi^2(J-K),
\end{displaymath}](img76.gif) |
(8) |
where HN is a
vector of moment conditions,
is a
vector of parameters,
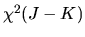 is a Chi-squared random variable with J-K degrees of freedom,
is a Chi-squared random variable with J-K degrees of freedom,
and
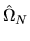 is a consistent estimator of
is a consistent estimator of 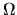 given by
given by
Hint: Use Taylor series expansions to provide
a formula for
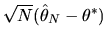 from the first order
condition for
from the first order
condition for
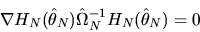 |
(9) |
and a Taylor series expansion of
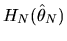 about
about
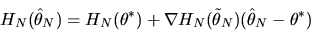 |
(10) |
where
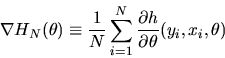 |
(11) |
is the
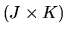 matrix of partial derivatives of the moment
conditions
matrix of partial derivatives of the moment
conditions
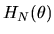 with respect to
and
with respect to
and
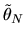 is a vector each of whose elements are on the line segment joining the
corresponding components of
and .
Use the above
two equations to derive the following formula for
is a vector each of whose elements are on the line segment joining the
corresponding components of
and .
Use the above
two equations to derive the following formula for
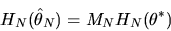 |
(12) |
where
![\begin{displaymath}M_N= \left[ I - \nabla H_N(\hat\theta_N)[\nabla H_N(\hat\thet...
...N)]^{-1} \nabla
H_N(\hat\theta_N)' \hat\Omega^{-1}_N \right]. \end{displaymath}](img92.gif) |
(13) |
Show that with probability 1 we have 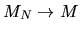 where M is a
where M is a
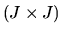 idempotent matrix. Then using this result, and using
the Central Limit Theorem to show that
idempotent matrix. Then using this result, and using
the Central Limit Theorem to show that
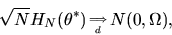 |
(14) |
and using the probability result from Question 0 of Part II,
show that the minimized value of the GMM criterion function
does indeed converge in distribution to the
random
variable as claimed in equation (8).
QUESTION 2 (Consistency of Bayesian posterior)
Consider a Bayesian who has observes
IID data
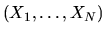 ,
where
,
where
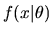 is the likelihood for a single observation,
and
is the likelihood for a single observation,
and 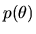 is the prior density
over
an unknown finite-dimensional parameter
is the prior density
over
an unknown finite-dimensional parameter
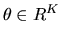 .
.
- A.
- (10%) Use Bayes Rule to derive a formula for the
posterior density of
given
.
- B.
- (20%) Let
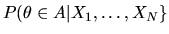 be the posterior probability
is in some set
be the posterior probability
is in some set
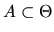 given the first
N observations. Show that this posterior probability
satisfies the Law of iterated expectations:
given the first
N observations. Show that this posterior probability
satisfies the Law of iterated expectations:
- C.
- (20%) A martingale
is a stochastic process
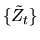 that satisfies
that satisfies
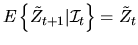 ,
where
,
where
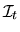 denotes the information set at time t and
includes knowledge of all past Zt's up to time t,
denotes the information set at time t and
includes knowledge of all past Zt's up to time t,
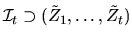 .
Use the
result in part A to show that the process
where
.
Use the
result in part A to show that the process
where
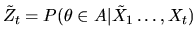 is a
martingale. (We are interested in martingales because
the Martingale Convergence Theorem can be used to show that
if
is finite-dimensional, then the posterior
distribution converges with probability 1 to a point mass on the
true value of
generating the observations
is a
martingale. (We are interested in martingales because
the Martingale Convergence Theorem can be used to show that
if
is finite-dimensional, then the posterior
distribution converges with probability 1 to a point mass on the
true value of
generating the observations 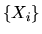 .
But
you don't have to know anything about this to answer this question.)
.
But
you don't have to know anything about this to answer this question.)
- D.
- (50%) Suppose that if
is restricted to the
K-dimensional
simplex,
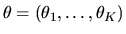 with
with
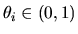 ,
,
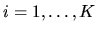 ,
,
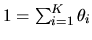 ,
and the distribution
of Xi given
is multinomial with parameter ,
i.e.
,
and the distribution
of Xi given
is multinomial with parameter ,
i.e.
Suppose the prior distribution over ,
is Dirichlet with parameter 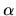 :
:
where both
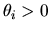 and
and
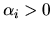 ,
.
Compute
the posterior distribution and show 1) the posterior is also
Dirichlet (i.e. the Dirichlet is a conjugate family),
and show directly that
as
,
.
Compute
the posterior distribution and show 1) the posterior is also
Dirichlet (i.e. the Dirichlet is a conjugate family),
and show directly that
as
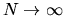 that the posterior distribution converges to
a point mass on the true parameter
generating the data.
that the posterior distribution converges to
a point mass on the true parameter
generating the data.
QUESTION 3
Consider the random utility model:
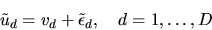 |
(15) |
where
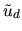 is a decision-maker's payoff or utility for selecting
alternative d from a set containing D possible alternatives (we
assume that the individual only chooses one item). The term vd is
known as the deterministic or strict utility from alternative
d and the error term
is a decision-maker's payoff or utility for selecting
alternative d from a set containing D possible alternatives (we
assume that the individual only chooses one item). The term vd is
known as the deterministic or strict utility from alternative
d and the error term
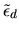 is the random component of
utility. In empirical applications vd is often specified as
is the random component of
utility. In empirical applications vd is often specified as
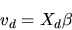 |
(16) |
where Xd is a vector of observed covariates and
is a vector
of coefficients determining the agent's utility to be estimated. The
interpretation is that Xd represents a vector of characteristics
of the decision-maker and alternative d that are observable
by the econometrician and
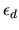 represents characteristics
of the agent and alternative d that affect the utility of choosing
alternative d which are unobserved by the econometrician. Define
the agent's decision rule
represents characteristics
of the agent and alternative d that affect the utility of choosing
alternative d which are unobserved by the econometrician. Define
the agent's decision rule
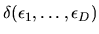 by:
by:
![\begin{displaymath}\delta(\epsilon) = \mbox{\it argmax\/}_{d=1,\ldots,D} \left[ v_d +
\tilde \epsilon_d\right] \end{displaymath}](img125.gif) |
(17) |
i.e.
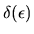 is the optimal choice for an agent whose
unobserved utility components are
is the optimal choice for an agent whose
unobserved utility components are
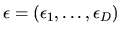 .
Then the agent's choice
probability
.
Then the agent's choice
probability 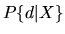 is given by:
is given by:
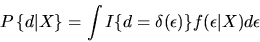 |
(18) |
where
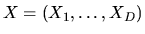 is the vector of observed characteristics of
the agent and the D alternatives and
is the vector of observed characteristics of
the agent and the D alternatives and
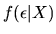 is the
conditional density function of the random components of utility given
the values of observed components X, and
is the
conditional density function of the random components of utility given
the values of observed components X, and
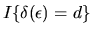 is the indicator function given by
is the indicator function given by
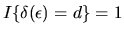 if
if
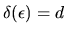 and 0 otherwise.
Note that the integral above is
actually a multivariate integral over the D components of
,
and simply represents the
probability that the values of the vector of unobserved utilities lead the agent to choose alternative d.
and 0 otherwise.
Note that the integral above is
actually a multivariate integral over the D components of
,
and simply represents the
probability that the values of the vector of unobserved utilities lead the agent to choose alternative d.
Definition: The Social Surplus Function
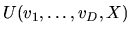 is given by:
is given by:
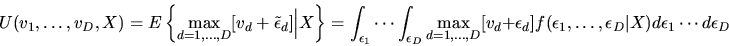 |
(19) |
The Social Surplus function is the expected maximized utility of the
agent.1
- A.
- (50%) Prove the Williams-Daly-Zachary Theorem:
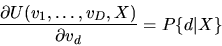 |
(20) |
and discuss its relationship to Roy's Identity.
-
- Hint: Interchange the differentiation and expectation
operations when computing
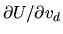 :
:
and show that
- B.
- (50%) Consider the special case of
the random utility model when
has a multivariate (Type I) extreme value distribution:
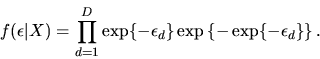 |
(21) |
Show that the conditional choice probability
is given by
the multinomial logit formula:
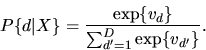 |
(22) |
Hint 1: Use the Williams-Daly-Zachary Theorem, showing
that in the case of the extreme value distribution (21) the Social
Surplus function is given by
![\begin{displaymath}U(v_1,\ldots,v_D,X)= \gamma+ \log\left[ \sum_{d=1}^D \exp\{ v_d\} \right].
\end{displaymath}](img143.gif) |
(23) |
where
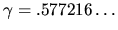 is Euler's constant.
is Euler's constant.
Hint 2: To derive equation (23) show that the
extreme value family is max-stable: i.e. if
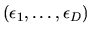 are IID extreme value random variables, then
are IID extreme value random variables, then
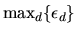 also has an extreme value distribution. Also
use the fact that the expectation of a single extreme value random
variable with location parameter
and scale parameter
also has an extreme value distribution. Also
use the fact that the expectation of a single extreme value random
variable with location parameter
and scale parameter
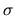 is given by:
is given by:
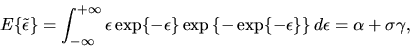 |
(24) |
and the CDF is given by
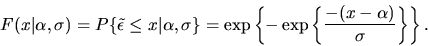 |
(25) |
Hint 3: Let
be
INID (independent, non-identically distributed) extreme value
random variables with location parameters
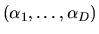 and common scale parameter .
Show that this family is
max-stable by proving that
and common scale parameter .
Show that this family is
max-stable by proving that
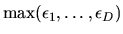 is an extreme
value random variable with scale parameter
and location parameter
is an extreme
value random variable with scale parameter
and location parameter
![\begin{displaymath}\alpha = \sigma \log\left[ \sum_{d=1}^D \exp\{ \alpha_d/\sigma\}
\right] \end{displaymath}](img152.gif) |
(26) |
QUESTION 4 (Latent Variable Models) The Binary
Probit Model can be viewed as a simple type of latent variable
model. There is an underlying linear regression model
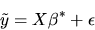 |
(27) |
but where the dependent variable 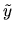 is latent, i.e.
it is not observed by the econometrician. Instead we observe the
dependent variable y given by
is latent, i.e.
it is not observed by the econometrician. Instead we observe the
dependent variable y given by
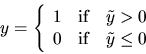 |
(28) |
- 1.
- (5%) Assume that the error term
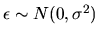 .
Show
that the scale of
and the
parameter
is not simultaneously identified and therefore without
loss of generality we can normalize
.
Show
that the scale of
and the
parameter
is not simultaneously identified and therefore without
loss of generality we can normalize
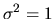 and interpret the
estimated
coefficients as being the true coefficients divided by :
and interpret the
estimated
coefficients as being the true coefficients divided by :
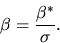 |
(29) |
- 2.
- (10%) Derive the conditional probability
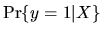 in terms of X,
and the standard normal CDF,
in terms of X,
and the standard normal CDF, 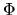 and use
this probability to write down the likelihood function for NIID observations of pairs
and use
this probability to write down the likelihood function for NIID observations of pairs
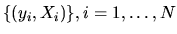 .
.
- 3.
- (20%) Show that
can
be consistently estimated by nonlinear
least squares by writing down the least squares problem and
sketching a proof for its consistency.
- 4.
- (20%) Derive the asymptotic distribution of the maximum
likelihood estimator by providing an analytical formula for the
asymptotic covariance matrix of the MLE estimator
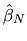 (Hint: This is the inverse of the information matrix
(Hint: This is the inverse of the information matrix
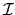 .
Derive a formula for
in terms of ,
X and
and possibly other terms.)
.
Derive a formula for
in terms of ,
X and
and possibly other terms.)
- 5.
- (20%) Derive the asymptotic distribution of the nonlinear
least squares estimator and compare it to the maximum likelihood
estimator. Is the nonlinear least squares estimator asymptotically
inefficient?
- 6.
- (25%) Show that the nonlinear least squares estimator
of
is subject to heteroscedasticity by deriving an
explicit formula for the conditional variance of the error term
in the nonlinear regression formulation of the estimation problem.
Can you form a more efficient
estimator by correcting for this heteroscedasticity in a two
stage feasible GLS procedure (i.e. in stage 1 computing an initial
consistent, but inefficient estimator of
by ordinary
nonlinear least squares and in stage two using this initial consistent
estimator to correct for the heteroscedasticity and using the stage
two estimator of
as the feasible GLS estimator)? If so,
is this feasible GLS procedure asymptotically efficient? If you
believe so, provide a sketch of the derviation of the asymptotic
distribution of the feasible GLS estimator. Otherwise provide a
counterexample or a sketch of an argument why you believe the
feasible GLS procedure is asymptotically
inefficient relative to the maximum likelihood estimator.
Next: About this document ...
John Rust
2001-04-27